SELECT *
FROM c_inout_i_v i
WHERE EXISTS (SELECT 1 FROM c_inout_z_v z
WHERE i.id_z_v = z.id_z_v AND z.f_date <'020201')
выполняется 0.03 секSELECT i.* FROM c_inout_i_v i, c_inout_z_v z WHERE i.id_z_v = z.id_z_v AND z.f_date <'020201'выполняется 11 сек
SELECT *
FROM c_inout_i_v i
WHERE i.id_z_v IN (SELECT z.id_z_v FROM c_inout_z_v z
WHERE z.f_date <'020201')
выполняется 11 секВ данном случае EXISTS работает крайне неэффективно. Для каждой строки маленькой таблицы перебирается очень большая таблица
SELECT ID_NUM_ACC
FROM LIST_ACC LA
WHERE EXISTS (SELECT 1 FROM SALDO_ACC SA
WHERE DAY >= '10.04.02' AND DAY <= '15.04.02' AND SA.ID_NUM_ACC = LA.ID_NUM_ACC
AND ID_CLIENT = 1 AND ID_CUR = 1 )
ORDER BY NUM_ACC
 t = 20 сек
t = 20 сек
SELECT ID_NUM_ACC SELECT la.ID_NUM_ACC FROM LIST_ACC LA ,( SELECT DISTINCT(ID_NUM_ACC) FROM SALDO_ACC WHERE DAY >= '10.04.02' AND DAY <= '15.04.02' AND ID_CLIENT = 1 AND ID_CUR = 1) sa WHERE SA.ID_NUM_ACC = LA.ID_NUM_ACC ORDER BY la.NUM_ACC
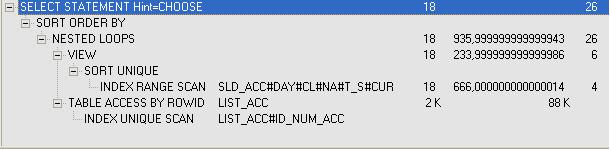 t = 0,2 сек
t = 0,2 сек
Использование /*+ RULE */ для простого запроса позволяет улучшить ситуацию,
но EXISTS всё же лучше.
В запросе с использованием IN управляющей таблицей является подзапрос указанный
в IN(), основной запрос повторяется для каждой строки возвращаемой подзапросом
в IN(). В запросе с использованием EXISTS наоборот, управляющим является основной
запрос, и подзапрос указанный в EXISTS() повторяется для каждой строки, выбираемой
в основном запросе.
Таким образом, если подзапрос возвращает малое количество строк, а основной
запрос возвращает большое количество строк причем для каждой из строк полученных
в подзапросе, то следует использовать оператор IN.
Отличные статьи на тему применения in & exists и not in & not_exists